UReader
Brands
Sign in
Sign up
Newsletter Search Engine
Dates
2025 (205704)
2026 (58826)
2024 (51094)
Business Categories
General
(100344)
Other
(57360)
Home
(22003)
Fashion
(21043)
Electronics
(16643)
Literature
(11218)
Sports
(11127)
Art
(8539)
Machinery
(5010)
Health
(4661)
Food
(2922)
Country
GLOBAL
(36396)
CO
(19584)
NL
(17254)
AU
(16822)
GB
(14895)
NZ
(14850)
US
(13578)
BE
(13180)
DE
(8928)
FI
(8613)
CL
(7680)
CA
(7465)
PL
(7322)
RO
(7149)
ES
(6757)
HU
(6517)
ZA
(6450)
AR
(5995)
IL
(5966)
DK
(5647)
FR
(5317)
SK
(5231)
BR
(5174)
HR
(5088)
IT
(4989)
CZ
(4662)
PT
(4497)
SE
(4483)
IE
(3860)
GR
(3828)
NO
(3796)
SG
(3148)
CH
(3061)
BG
(2924)
RU
(2625)
MY
(2290)
UA
(2266)
MX
(2169)
AT
(2132)
JP
(2125)
PE
(1850)
RS
(1775)
TR
(757)
VE
(753)
IO
(670)
TW
(590)
ID
(590)
PK
(577)
IQ
(543)
HK
(499)
MA
(476)
PH
(440)
TV
(410)
AE
(318)
TH
(252)
KW
(188)
KP
(108)
VN
(54)
EG
(42)
IN
(8)
KZ
(4)
MD
(2)
NU
(2)
LT
(1)
BA
(1)
LK
(1)
Total 315624 mails
helander
FI
·
2026-6-15
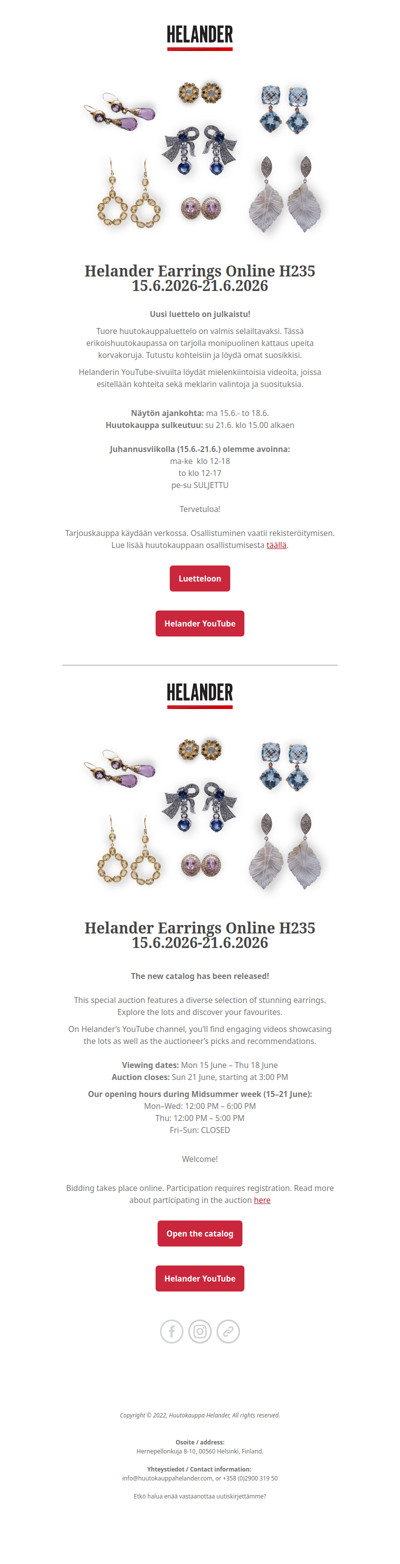
Uusi luettelo julkaistu! New catalog published!
e-wheels
NO
·
2026-6-15
Gjør et kupp nå! Spar opptil 50% nå ☀️⚡
steepandcheap
US
·
2026-6-15
🚨 Last day for an extra $75 off
thenorthface
CL
·
2026-6-15
Aún estás a tiempo de encontrar el regalo perfecto
motorola
AR
·
2026-6-15
🎁 Últimos días para regalarle lo mejor, al mejor
therealreal
GLOBAL
·
2026-6-15
These are about to go quick
cashbackdeals
BE
·
2026-6-15
Scoor nu 25% korting op je abonnement
libromar
CL
·
2026-6-15
Código tributario de Chile 2026 Tirant lo Blanch (Antonio Faúndez U.)
Cinema World
IL
·
2026-6-15
, : מסך של LG במחיר נדיר 😲 >> פרסומת
shogun
NL
·
2026-6-15
Hi Rambo 👊 geef ze een duidelijke Vaderdag hint!
comfy
UA
·
2026-6-15
✨До -50% без приводу
bellababy
IE
·
2026-6-15
Forget something?
1
2
3
4
5
©2024 UReader
Home
Brands
Marked Emails
Followed Brands
Privacy Policy & User Agreement