UReader
Brands
Sign in
Sign up
Newsletter Search Engine
Dates
2025 (205704)
2026 (57295)
2024 (51094)
Business Categories
General
(99904)
Other
(57144)
Home
(21871)
Fashion
(20913)
Electronics
(16556)
Literature
(11182)
Sports
(11053)
Art
(8491)
Machinery
(5000)
Health
(4654)
Food
(2907)
Country
GLOBAL
(36176)
CO
(19573)
NL
(17191)
AU
(16705)
GB
(14829)
NZ
(14755)
US
(13516)
BE
(13139)
DE
(8886)
FI
(8556)
CL
(7644)
CA
(7436)
PL
(7294)
RO
(7127)
ES
(6741)
HU
(6477)
ZA
(6413)
IL
(5950)
AR
(5934)
DK
(5630)
FR
(5284)
SK
(5214)
BR
(5153)
HR
(5061)
IT
(4973)
CZ
(4640)
PT
(4480)
SE
(4452)
IE
(3831)
GR
(3811)
NO
(3773)
SG
(3131)
CH
(3042)
BG
(2908)
RU
(2605)
MY
(2272)
UA
(2246)
MX
(2150)
AT
(2120)
JP
(2117)
PE
(1846)
RS
(1760)
TR
(755)
VE
(750)
IO
(667)
ID
(589)
TW
(586)
PK
(575)
IQ
(540)
HK
(497)
MA
(476)
PH
(435)
TV
(408)
AE
(315)
TH
(248)
KW
(188)
KP
(108)
VN
(54)
EG
(42)
IN
(8)
KZ
(4)
MD
(2)
NU
(2)
LT
(1)
BA
(1)
LK
(1)
Total 314093 mails
telavendo
AR
·
2026-6-11
💙Telas Mundialistas: Celeste y Blanco para crear!
ostercolombia
CO
·
2026-6-11
Hasta 40% OFF
bradsdeals
US
·
2026-6-11
More Deals You’ll Love—Just for You!
bigw
AU
·
2026-6-11
Big Tech. Big Gaming. Big Fun. 🎮
devre
AR
·
2026-6-11
¡Solo por hoy! 30% OFF + Cupón 15% EXTRA en CHALECOS 🔥
frontiertouring
GLOBAL
·
2026-6-11
🎼 Rick Beato brings his live show to Aus + NZ for the first time
bravojeans
AR
·
2026-6-11
Vení a elegir el regalo
thinlizzy
NZ
·
2026-6-11
Curls That Drop Out? Lock Them In!
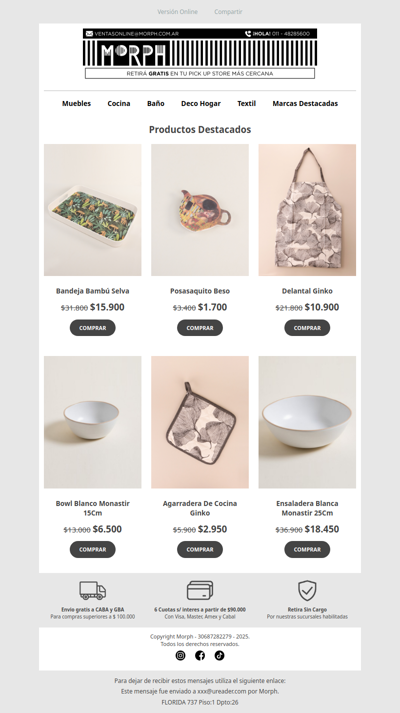
morph
AR
·
2026-6-11
Accesorios para la cocina con 50% off🔥 Descuentos por tiempo limitado!
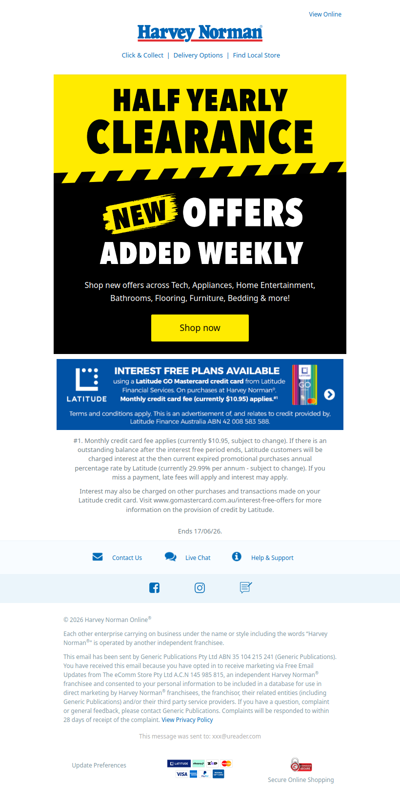
harveynorman
AU
·
2026-6-11
New Offers Added | Storewide Half Yearly Clearance Deals
bogsfootwear
AU
·
2026-6-11
Keep Your Toes Toasty
carolineeve
NZ
·
2026-6-11
Found the hidden gems of the season 💎
1
2
3
4
5
©2024 UReader
Home
Brands
Marked Emails
Followed Brands
Privacy Policy & User Agreement