UReader
Brands
Sign in
Sign up
Newsletter Search Engine
Dates
2025 (205704)
2026 (58627)
2024 (51094)
Business Categories
General
(100284)
Other
(57332)
Home
(21988)
Fashion
(21024)
Electronics
(16627)
Literature
(11214)
Sports
(11117)
Art
(8535)
Machinery
(5009)
Health
(4660)
Food
(2918)
Country
GLOBAL
(36373)
CO
(19583)
NL
(17244)
AU
(16816)
GB
(14888)
NZ
(14839)
US
(13574)
BE
(13174)
DE
(8920)
FI
(8600)
CL
(7678)
CA
(7461)
PL
(7320)
RO
(7147)
ES
(6754)
HU
(6510)
ZA
(6439)
AR
(5987)
IL
(5962)
DK
(5645)
FR
(5312)
SK
(5230)
BR
(5171)
HR
(5083)
IT
(4986)
CZ
(4659)
PT
(4493)
SE
(4481)
IE
(3854)
GR
(3825)
NO
(3795)
SG
(3146)
CH
(3059)
BG
(2919)
RU
(2622)
MY
(2286)
UA
(2262)
MX
(2169)
AT
(2131)
JP
(2125)
PE
(1849)
RS
(1772)
TR
(756)
VE
(753)
IO
(670)
ID
(590)
TW
(589)
PK
(577)
IQ
(543)
HK
(499)
MA
(476)
PH
(440)
TV
(410)
AE
(317)
TH
(251)
KW
(188)
KP
(108)
VN
(54)
EG
(42)
IN
(8)
KZ
(4)
MD
(2)
NU
(2)
LT
(1)
BA
(1)
LK
(1)
Total 315425 mails
jossandmain
US
·
2026-6-15
Your next *it* piece? The eustacia table lamp
hsn
GLOBAL
·
2026-6-15
You Picked a Good One: Berberine Phospholipid Complex
westelm
GLOBAL
·
2026-6-15
Free design help for your outdoor setup
smartbuyglasses
ZA
·
2026-6-15
Time to upgrade your lenses
flowerstore
PH
·
2026-6-15
Payday Sale is here — and Father's Day is in 6 days 👔
mamilove
TW
·
2026-6-15
📚【期末考神助手】OneStudy+全面6折!
itvsn
AU
·
2026-6-15
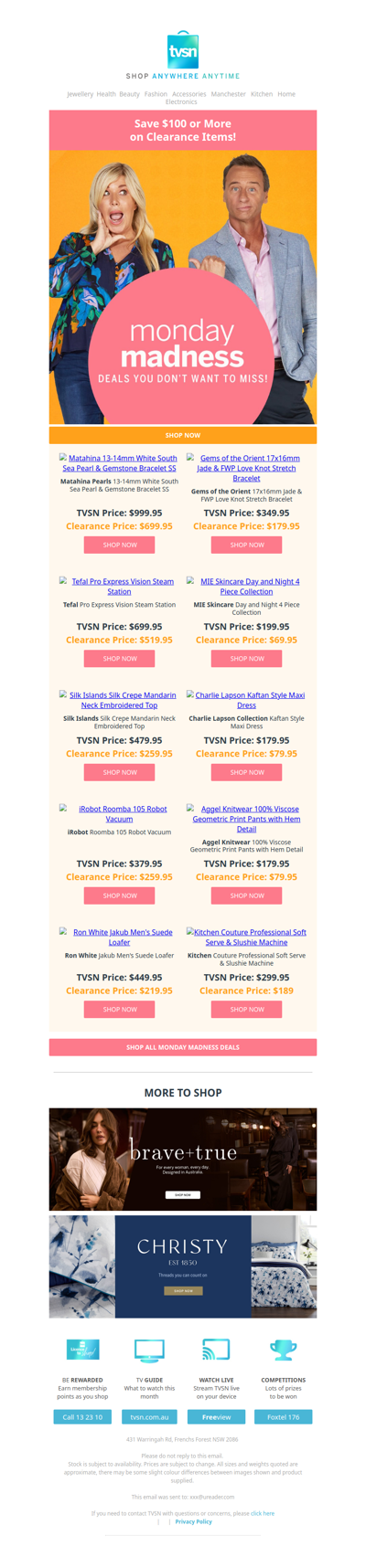
Monday Madness: Save $100 or More on Clearance Items!
opticsplanet
GLOBAL
·
2026-6-15
HUGE Inventory Liquidation Sale!
bookgrocer
AU
·
2026-6-15
EOFY sale: 20% off Book Boxes⚠️📦
harveynorman
NZ
·
2026-6-15
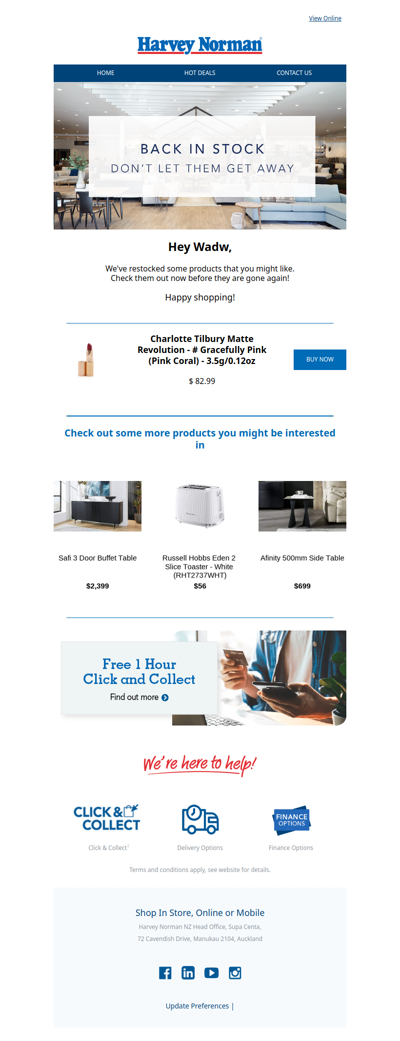
THEY'RE BACK! We restocked our most-wanted items.
tvsn
NZ
·
2026-6-15
Monday Madness: Save $100 or More on Clearance Items!
masonline
AR
·
2026-6-15
🛒 Planificá tu semana para ahorrar Mâs 🤗
1
2
3
4
5
©2024 UReader
Home
Brands
Marked Emails
Followed Brands
Privacy Policy & User Agreement