Newsletter Search Engine
Total 317788 mails







kogan
GLOBAL
·
2026-6-22
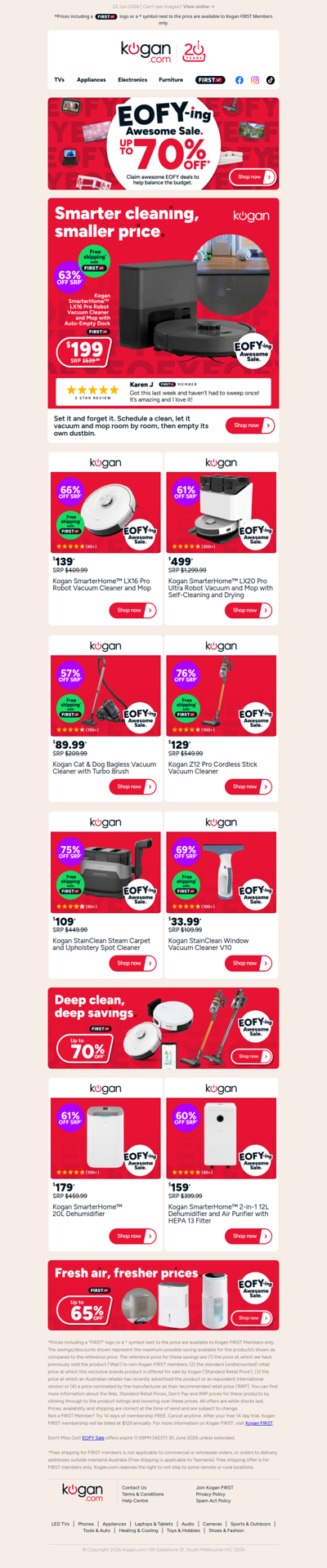
ONLY $199 for this SmarterHome™ Auto-Empty Robot Vac and Mop (63% OFF standard retail price)
Newsletter Search Engine