Newsletter Search Engine
Total 314341 mails



morph
AR
·
2026-6-11
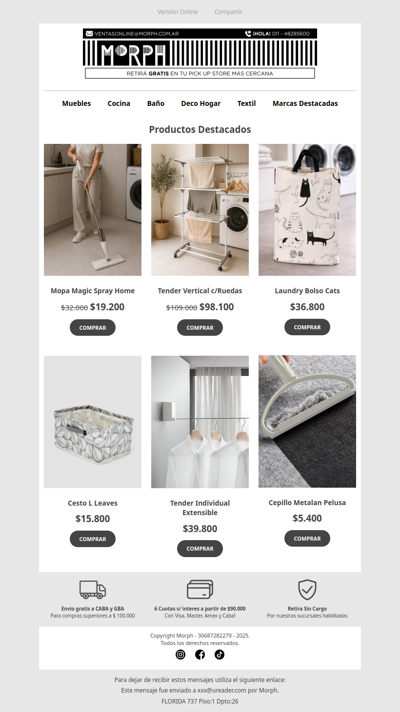
Tu casa limpia y organizada con nuestros productos en promo 🧺 Descuentos por tiempo limitado!



libromar
CL
·
2026-6-11

Derecho de daños y responsabilidad civil - Revisión de temas actuales y futuros - Tomo II (Gian Franco Rosso E. – José Antonio Espinosa F.)

