Newsletter Search Engine
Total 317376 mails







proxibid
US
·
2026-6-20
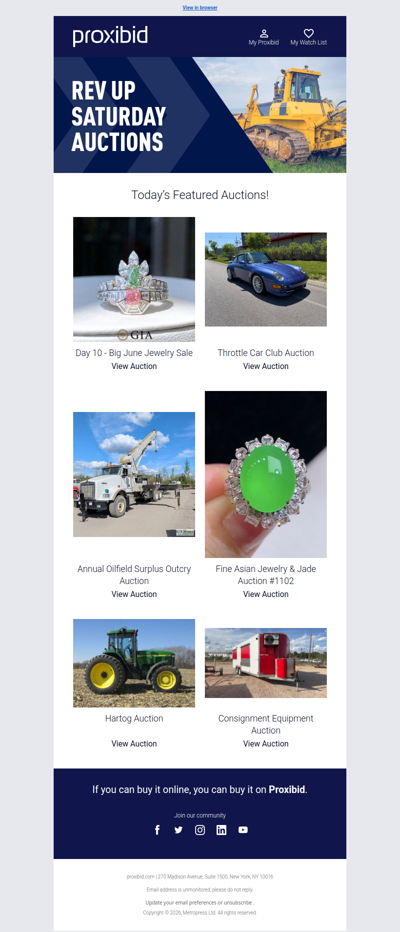
Last Chance: Heavy Equipment, Farm Machinery, Collector Cars, & More - Bid Now!
Newsletter Search Engine