Newsletter Search Engine
Total 314320 mails
sears
GLOBAL
·
2026-6-11
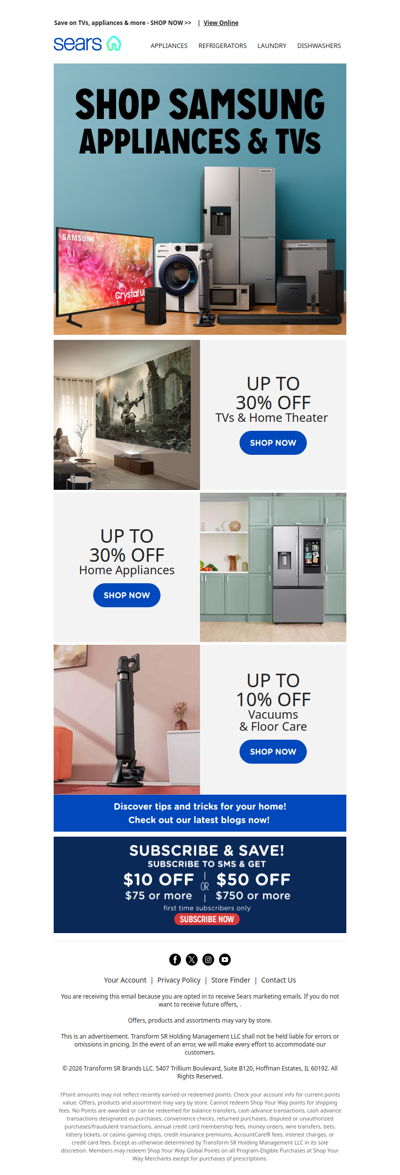
Samsung's calling! 📺✨ Unleash your inner chef and binge-watcher with up to 30% off! 🥳




vouchercloud
GB
·
2026-6-11
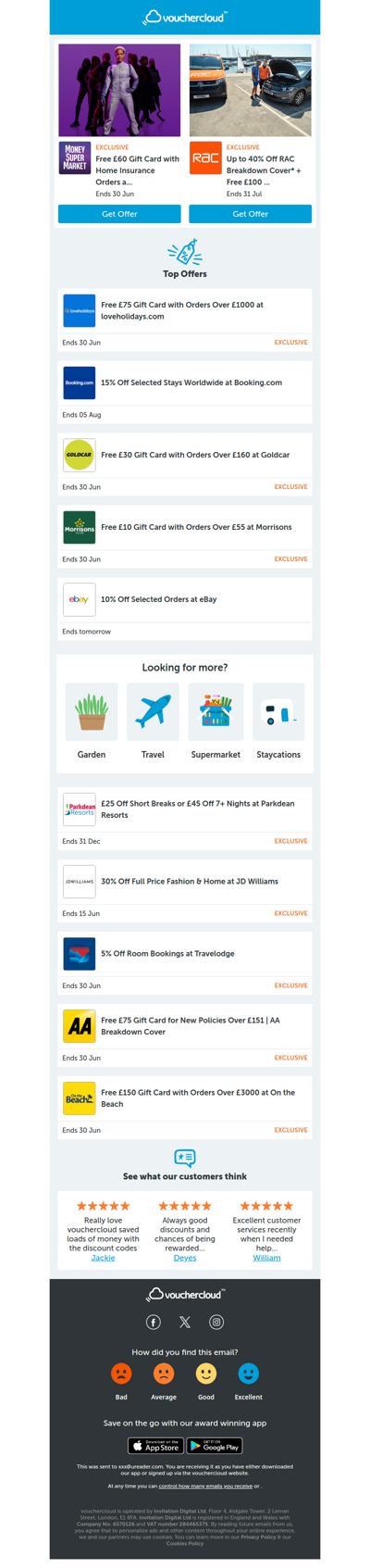
Morrisons - £10 gift card • RAC Breakdown - £100 gift card • Booking.com - 15% off + more!