Newsletter Search Engine
Total 314463 mails
bazarhorizonte
BR
·
2026-6-12

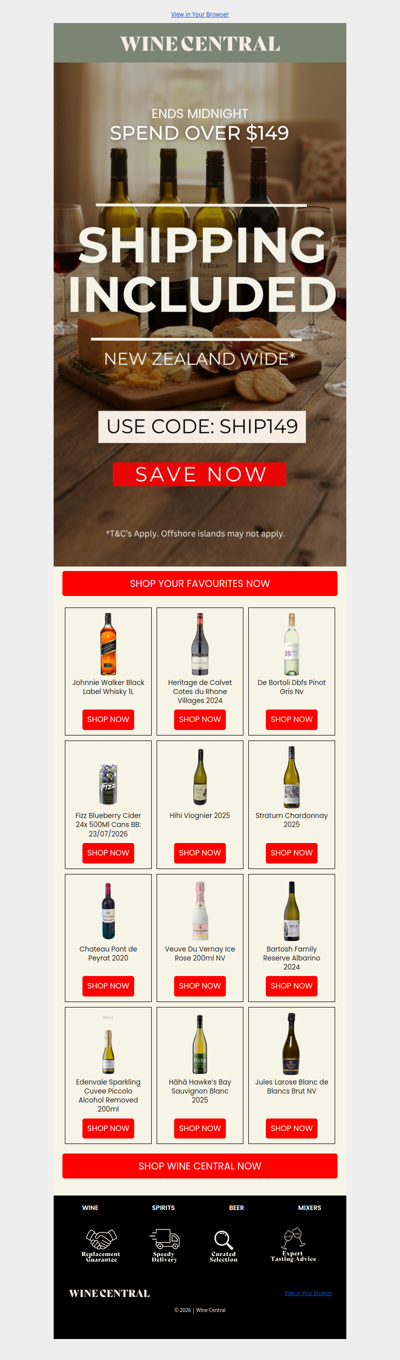
💚 Amarelinho na agulha! Venha torcer pelo Brasil com o Bazar Horizonte! 🧡



cordys
NZ
·
2026-6-12
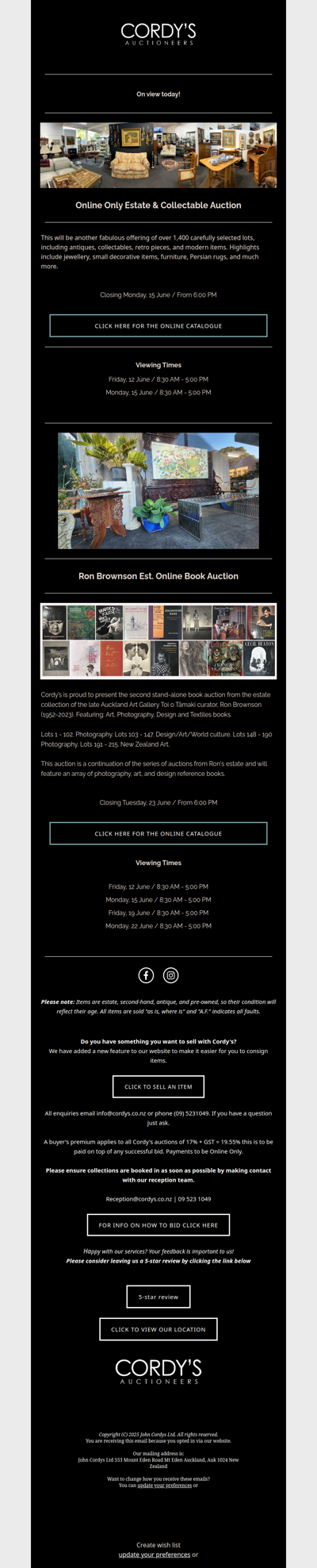
Online Only Estate & Collectable Auction and Ron Brownson est. online book auction pt.2