UReader
Brands
Sign in
Sign up
Newsletter Search Engine
Dates
2025 (205704)
2026 (62012)
2024 (51094)
Business Categories
General
(101286)
Other
(57865)
Home
(22267)
Fashion
(21273)
Electronics
(16806)
Literature
(11307)
Sports
(11260)
Art
(8631)
Machinery
(5038)
Health
(4691)
Food
(2954)
Country
GLOBAL
(36856)
CO
(19602)
NL
(17377)
AU
(17062)
NZ
(15047)
GB
(15039)
US
(13726)
BE
(13265)
DE
(9003)
FI
(8706)
CL
(7771)
CA
(7539)
PL
(7388)
RO
(7202)
ES
(6804)
HU
(6578)
ZA
(6526)
AR
(6113)
IL
(6003)
DK
(5693)
FR
(5380)
SK
(5276)
BR
(5222)
HR
(5144)
IT
(5020)
CZ
(4697)
SE
(4539)
PT
(4535)
IE
(3928)
GR
(3852)
NO
(3844)
SG
(3187)
CH
(3102)
BG
(2954)
RU
(2667)
MY
(2320)
UA
(2296)
MX
(2214)
AT
(2158)
JP
(2145)
PE
(1871)
RS
(1805)
VE
(765)
TR
(765)
IO
(678)
TW
(595)
ID
(590)
PK
(580)
IQ
(552)
HK
(500)
MA
(476)
PH
(450)
TV
(414)
AE
(323)
TH
(255)
KW
(188)
KP
(108)
VN
(54)
EG
(42)
IN
(8)
KZ
(4)
MD
(2)
NU
(2)
LT
(1)
BA
(1)
LK
(1)
Total 318810 mails
tvsn
NZ
·
2026-6-25
Mid Year SALE continues | Up to 50% Off*
thenorthface
CL
·
2026-6-25
El sendero te espera. ¿Tienes el calzado correcto?
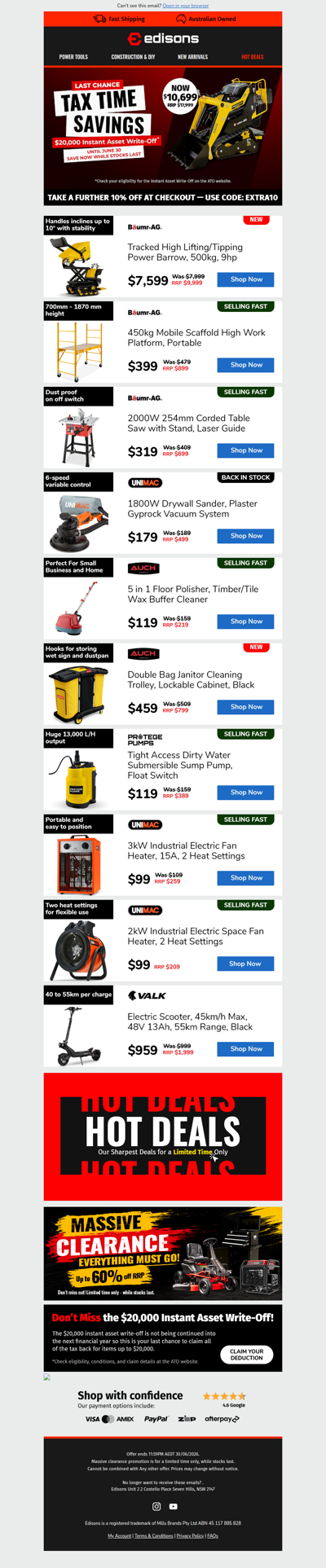
edisons
AU
·
2026-6-25
💼 Upgrade Before June 30 🛒
oster
CL
·
2026-6-25
Tu próxima cafetera con hasta 30% OFF
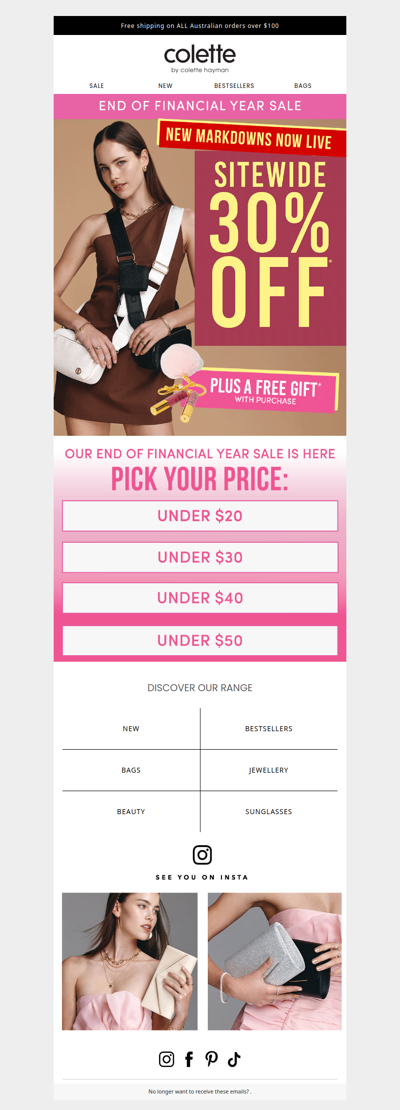
colettehayman
AU
·
2026-6-25
🤯 Under $20. Under $30. Under $40. All under the sale.
happybooks
CO
·
2026-6-25
⚡Solo para suscriptores: 5% extra con RELAMPAGO
bradsdeals
US
·
2026-6-25
Shop the Top Sales of Summer Now!
itvsn
AU
·
2026-6-25
Mid Year SALE continues | Up to 50% Off*
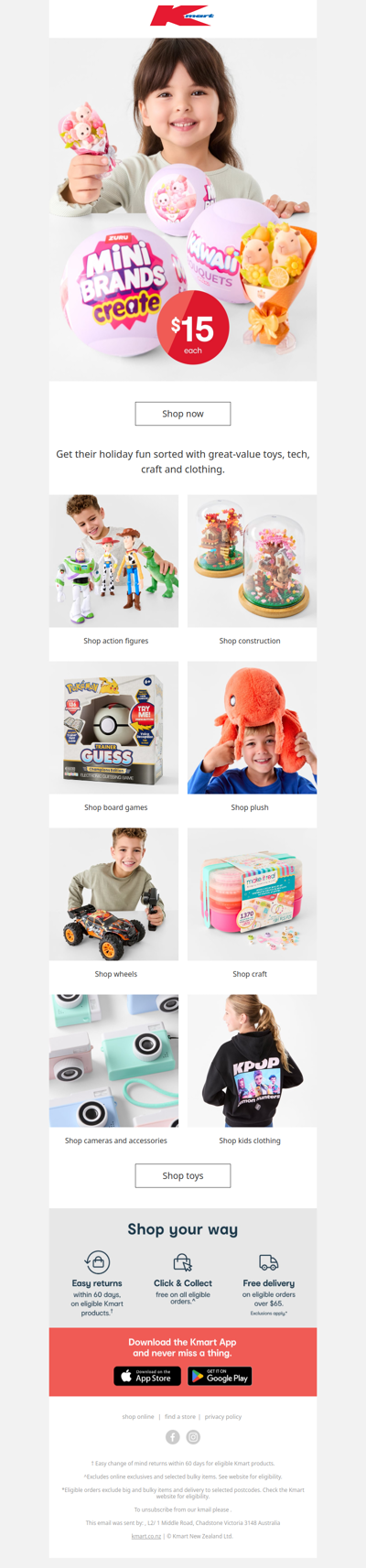
kmart
NZ
·
2026-6-25
School holiday smiles, low price joy 😄
babyinfanti
PE
·
2026-6-25
24 años contigo 💙 ¡Hoy celebramos con ofertas!
canningvale
GLOBAL
·
2026-6-25
These bathrooms may inspire a makeover 🤭
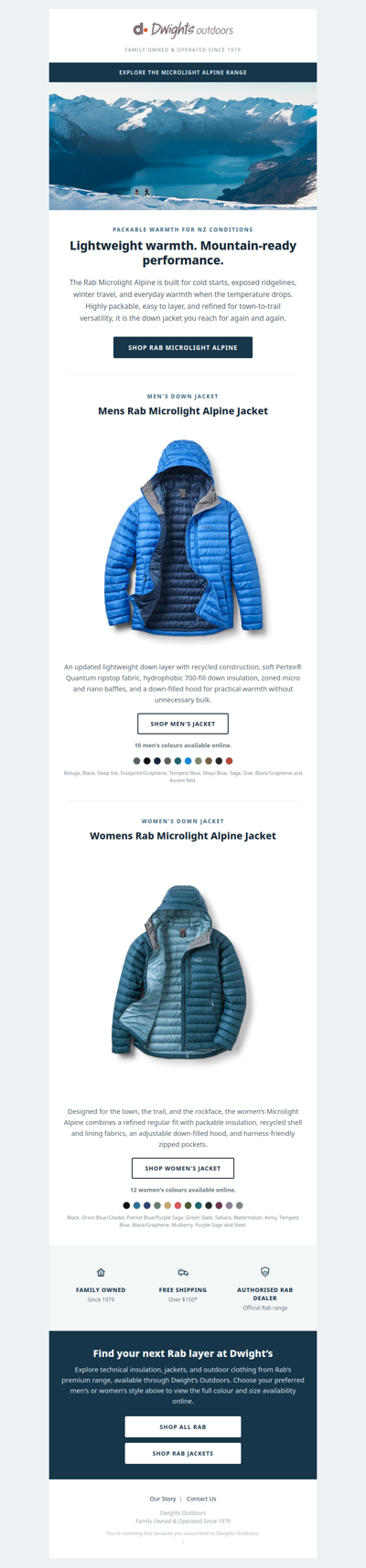
dwights
NZ
·
2026-6-25
Packable warmth from Rab, ready at Dwights
1
2
3
4
5
©2024 UReader
Home
Brands
Marked Emails
Followed Brands
Privacy Policy & User Agreement